Critiquing GenAI in First-Year Macroeconomics
Background
I teach an introductory macroeconomics module to 1st-year undergraduate students studying economics or business economics. The cohort is usually comprised of approximately 100 students, with a mix of economics and non-economics backgrounds; often students have no prior economics knowledge. The focus on the module is to get students acquainted with foundational macroeconomic theory and evidence. The assessment strategy is comprised of two coursework components: the first is an exercise where students evaluate a theoretical model using empirical data; the second assignment is essay-based.
With the rise of Generative AI (or GenAI), I have noticed a considerable shift in terms of academic misconduct. Rather than outright plagiarism, students often blindly output AI-generated content to pass off as their own work. This is perhaps a bigger risk for 1st-year modules, where students are often assessed in terms of how well they meet QAA threshold levels (see QAA, 2023), which AI tools can imitate reasonably well.
To me, the challenge was not so much to restrict student AI usage, or improve my ability to detect cases of misconduct, but to better embed AI into the assessment design. The objective was two-fold: to get students to engage with AI tools in a more ethical and constructive way, and to aid my discrimination between student ability. Consequently, the second coursework component was redesigned around AI usage.
Method
The redesigned assessment was a 2,500-word GenAI essay worth 65% of the module mark. The remaining 35% came from CW1. This meant the AI-integrated assessment was the main summative assessment in the module.
Students were provided with a set of macroeconomic exam-style essay questions to choose from. The questions focused on applications of macroeconomic theory to the study of the UK economy. Students were required to input their chosen question into a GenAI tool of their choice, and output the exact text, which should be approximately 750 words.
Students first had to comment on the essay using the comments function in MS Word. Comments were graded on their critical engagement. I was specifically examining whether students could competently identify instances where the AI was correct, where it was incorrect, where it lacked detail or context, and whether sufficient evidence was provided, as well as evaluating any sources.
Secondly, students had to edit the original AI output into a 1,000-word essay, using track changes. Students were made aware that missing track changes would result in severe marking penalties. Alongside track changes, students had to comment on their edits, explaining or outlining what purpose they served. This forced students to link back to their original critical engagement; students had to connect their edits with their initial criticisms.
Third, students wrote a 750-word reflection on their experience using GenAI. This asked them to discuss the strengths and limitations of the AI output, explain how they improved it, identify any sources or theories used in their revisions, and reflect on how the process affected their understanding of both the topic and ethical AI use. Students also submitted screenshots of all prompts and AI outputs, including any follow-up prompts, with comments on how prompt design influenced the quality of the response.
The marking scheme reflected these priorities. The critique of AI output was worth 20%, the revised explanation 30%, the reflection 30%, prompt design and screenshots 10%, and presentation and clarity 10%. The rubric rewarded students for identifying specific strengths, weaknesses, omissions, inaccuracies and oversimplifications; improving the AI answer using macroeconomic theory, data and academic sources; reflecting meaningfully on AI’s role in learning; and documenting their AI interaction transparently.
The purpose of incorporating both comments and track changes was deliberate. First, it forced students to think about their critiques and edits in more detail as they had to justify their approach. Second, GenAI tools, at the time of writing, are not able to accurately replicate comments or track changes on their own. It also meant that student timings could be tracked for suspicious activity. This discouraged students simply inputting the assignment brief into a GenAI model and requesting an output file.
Student preparation
Students were prepared for the task through seminars and online guidance. In seminars, students practised using short AI prompts that produced outputs of around 100–200 words. These short outputs were then critiqued in class. This allowed students to practise their critical engagement skills by putting their theoretical knowledge to work.
Three guidance videos were also provided alongside the coursework brief. One explained the assessment requirements, one covered using AI tools and prompt engineering, and one demonstrated how to use track changes and comments in MS Word. This was important because some students do not possess requisite skills using MS Office applications and may also have more limited experience with prompt engineering.
Finally, students were provided with a specimen submission that I had created. The specimen was restricted to an essay title that was not made available for students to choose from. I did note that most students used the specimen for inspiration when developing their own critiques and comments.
Outcomes
I compared the grade distributions of the 24/25 cohort, who operated under the non-AI assessment design, against the 25/26 cohort who did complete the AI assessment. Whilst there are obvious disclaimers against drawing anything serious from this comparison, it is still useful to highlight what benefits the new assessment design produced.
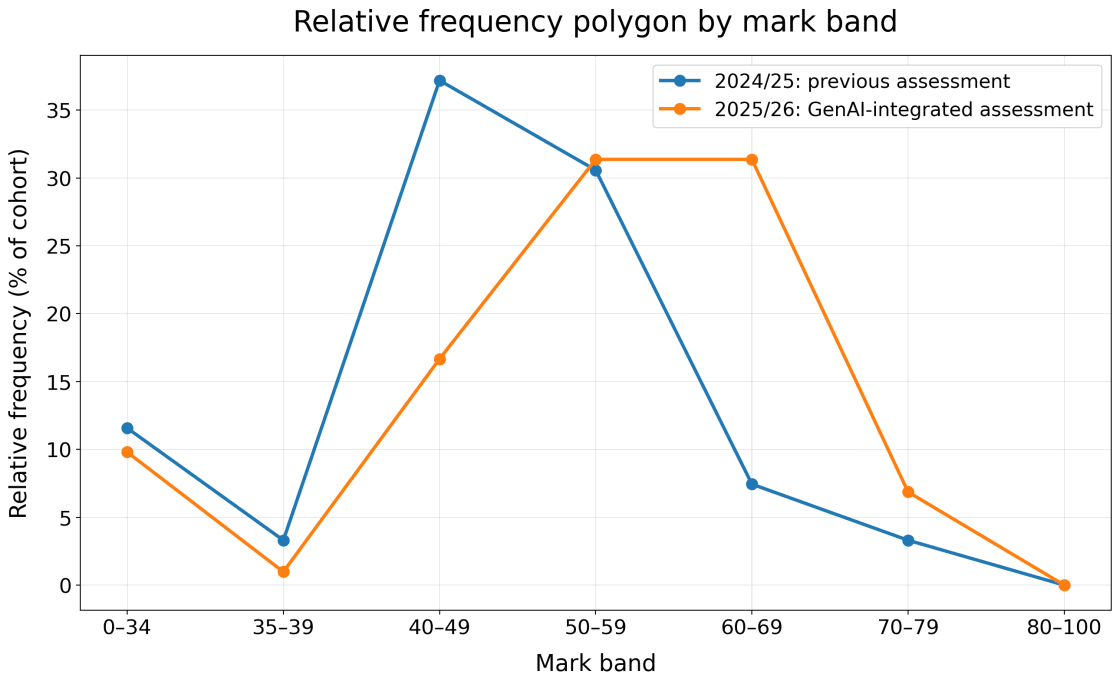
In 24/25, the overall module average was 46.82%. CW1 had an average mark of 48.65%, while CW2, the policy report, had an average mark of 45.81%. In 25/26, after the AI-integrated assessment was introduced, the overall module average increased slightly to 48.84%. CW1 rose substantially to 56%, while CW2 rose only marginally to 46.8%. At the same time, the distribution of marks shifted, as per Figure 1. In 24/25, the largest group of students fell into the 40-49% band. In 25/26, the largest groups were in the 50-59% and 60-69% bands. The proportion of students achieving 50% or above was higher in the AI-integrated year, while the proportion in the 40-49% band was lower.
Non-submission and disengagement remained significant. In 25/26, approximately 10% of students did not submit CW2, and some students who had not submitted CW1 submitted very weak work for CW2. By contrast, only 3% of students did not submit the previous year.
There were also practical academic integrity benefits. I noticed fewer cases of unethical AI use. However, the cases that did arise were particularly noticeable, usually because students failed to engage meaningfully with the required critique, revision, reflection, or prompt-documentation process.
Figure 1 Distribution of CW2 Grades before and after implementation of AI assessment
In particular, a small number of students attempted to use GenAI to output the full assessment, including track changes and comments. These were particularly easy to spot, as the AI placed comments within the text, rather than within comment boxes, whilst track changes were not produced. Consequently, the assessment did not eliminate misconduct, but it made the boundary between acceptable and unacceptable AI use easier to identify.
Informal student feedback was generally positive. Some students appeared surprised that AI tools did not always follow basic instructions, such as word-count limits, or that outputs could contain unsupported or inaccurate statistics. At the same time, some students struggled to identify what the AI had omitted or oversimplified. This was an important learning point: students may be able to spot obvious errors, but recognising missing theory, weak explanations or evaluation requires greater understanding of the material.
What I learned
The strongest submissions used the revision stage to make the macroeconomic theory integral to the essay. Stronger students identified where the AI had mentioned a model only superficially, then revised the answer to embed the model into the essay. They brought in relevant figures, diagrams, data, and supporting evidence to clarify the mechanism being discussed.
Weaker submissions often treated the task as proofreading. Some students made superficial language edits without substantially changing the economic content. Others produced comments on the AI output but did not link those comments to their subsequent revisions. This revealed an important gap between critique and improvement.
Overall, I think the assessment worked well to teach students responsible AI usage, whilst permitting a good differentiation between grade boundaries; the AI tool was no longer able to supplement a lack of student understanding.
What I would change
First, I would restrict the AI specimen submission to being reviewed in class. I think that widespread access to the specimen shaped how students thought about their critiques in both good and bad ways. For more competent students, it served as inspiration, whilst for weaker students, it inspired replication.
Second, I would include a short anonymous survey after submission. This would provide better evidence on student experience than informal comments alone. I would ask whether the task helped students understand macroeconomic writing, whether critiquing AI improved their confidence, and what they found most difficult.
Third, I would give students more practice in identifying omissions. Many students can recognise when an answer contains a clear error, but omissions are harder. Future seminar activities could therefore focus on questions such as: What theory is missing? What assumptions are unstated? What evidence would be needed? What diagram would clarify the argument?
Conclusion
First-year modules are perhaps most at risk of undisclosed or unethical AI usage from students, because their assessment content often requires students to display a foundational understanding of theoretical concepts. AI is particularly well suited towards outputting good quality content for students in this regard. By embedding AI usage into the assessment and requiring students to engage with AI using methods that are not easily replicable by the AI, I aimed to foster student understanding of foundational content, whilst testing their critical thinking skills.
Although this cannot be attributed directly to the assessment, I noticed in a second-semester statistical methods module that I also teach to 1st-years, fewer cases of AI misconduct, and more cases of declared AI usage. In one example, a student had engaged with AI to reformat the appearance of their submission. This is indicative that it is important to embed good AI literacy early-on.
References
Quality Assurance Agency for Higher Education (QAA) (2023) Subject Benchmark Statement: Economics. Gloucester: QAA. Available at: https://www.qaa.ac.uk/docs/qaa/sbs/sbs-economics-23.pdf (Accessed: 22 June 2026)
AI disclosure statement
I used ChatGPT to support the preparation of this case study. Its use was limited to editorial assistance, checking phrasing and structure, formatting references, and generating figures from anonymised grade-distribution data that I supplied. The assessment design, module context, interpretation of outcomes, pedagogical reflections, intellectual argument, and final editorial decisions are my own.
↑ Top