

A large number of papers have appeared in CHEER promoting the use of spreadsheets in teaching and learning economics. Judge (1990) and Taylor (1990) were amongst the first, while Wilder (1999) and Whigham and Whyte (1999) are among the most recent. This paper suggests yet another possible application - for implementing simple Monte Carlo studies on introductory econometrics courses.
The availability of relatively inexpensive computing power has allowed Monte Carlo studies to become an important part of modern econometrics. Researchers can investigate the properties (especially the small sample properties) of estimators and test procedures where results cannot be derived theoretically.
Using a computer, a large number of artificial or simulated data sets can be created according to a known data generation process. Then an estimator or test procedure can be applied to the artificial data sets so that the pattern of results obtained can be analysed and compared with the (known) features that were designed into the data. In this way investigators can get a measure of the extent of any inherent biases in the estimators or in the power of the test procedures under various conditions.
Students of economics and econometrics, even at undergraduate level, ought to be aware of the important contribution that such studies are having to the development of the subject. Indeed, there may be some educational value in getting them to conduct their own simple Monte Carlo exercises. This point has been recognised by the authors of such recent texts as Kennedy (1998) and Thomas (1997), both of whom provide a number of suggested Monte Carlo exercises for readers to work through.
The purpose of such exercises is not only to teach students about the use of Monte Carlo studies in a research context, for discovering properties of estimators and test procedures in situations where they cannot be derived analytically. It is also to help beginning student learners to understand concepts (such as the sampling distribution of a least squares estimator) which may be difficult for them to grasp when they have to rely solely on their imagination.
A modern spreadsheet package provides a very convenient environment for undergraduate students to use for simple Monte Carlo experiments. Most students will be comfortable in using such packages and they provide built-in functions that can be used to generate the random disturbances for the data generating process. They contain built-in least squares regression estimation procedures (or matrix tools if it is required to construct other estimators or test statistics). In addition they can provide summary statistics and graphical displays to enable students to assess patterns in the results obtained. It might be argued that other specialist econometrics software (or even packages like Mathematica or Maple) might be more natural tools for a researcher to use for Monte Carlo studies. However it can make sense for a student to work with a tool with which she is already familiar unless it is insufficient for the task in hand.
A couple of years ago I decided to include a simple Monte Carlo exercise, based on the use of the spreadsheet package Excel, in my second year undergraduate course “Introduction to Econometrics”. In Section 2 I describe the exercise and make some comments on the reactions of the students. Section 3 gives a few other ideas for simple spreadsheet based Monte Carlo exercises. Section 4 briefly concludes.
The purpose of this exercise was to help students to understand the meaning of the sampling distribution of a least squares regression estimator, and the way in which the properties of the sampling distribution reflect the characteristics of the regression model itself. In addition it was hoped to convey to the students something of the flavour of Monte Carlo studies in general.
The exercise was the third of twelve weekly exercises given to students on a one semester second year undergraduate course on econometrics. On entering the course the students should have had a basic understanding of the bivariate regression model (from their previous semester statistics course) and of the use of spreadsheets (from their Computing Skills for Economists and Economics Workshop courses).
As Kennedy notes there are four stages in A Monte Carlo study. The first stage is to construct a model of the data generation process. The students on my course were asked to assume that it took the form
Yi = a + bXi + ui [1]
with a=20 and b=0.6 and where ui is N(0,1).
A fixed set of 25 values for X was given as shown in Table 1. Any set of values could of course be used, but these values have a clearly recognizable mean and variance.
|
i |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
|
Xi |
88 |
89 |
90 |
91 |
92 |
93 |
94 |
95 |
96 |
97 |
98 |
99 |
100 |
|
i |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
|
|
Xi |
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
112 |
|
The second stage is to create sets of data. The students were asked to use the computer’s random number generator to generate 100 sets of 25 values of the random disturbance u by taking random drawings from the standard normal distribution (mean = 0, standard deviation = 1). In Excel version 5 this can be achieved by selecting Random Number Generation from the Data Analysis option on the Tools menu. So in the dialog box the Number of Variables is set at 100, the Number of Random Numbers is set at 25 and the Distribution is set to be Normal (see figure 1).
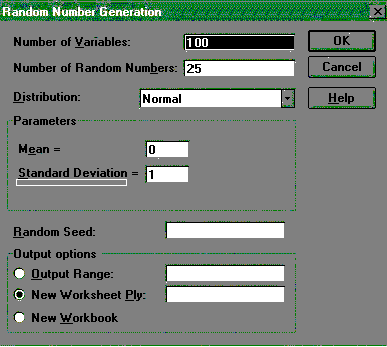
Figure 1: Generating the disturbance values
Now the student must create 100 sets of Y values to go with the u values, based on equation 1. This process is relatively straightforward, if a little tedious, with the student needing to enter the formula for the first observation of Y in each sample and then use the spreadsheet’s copying feature to produce the other 24 data points. Of course the X values are designed to remain fixed over the different samples.
In stage 3 the estimator is used with the artificial data sets to estimate the parameters of the model. I asked the students to run 100 regressions, using each of the samples of 25 observations on X and Y, and to extract the estimated slope coefficient and put them into a table.
Stage 4 is the analysis of the results. The students were asked to examine the distribution of the set of estimates obtained, calculating the mean and variance. They were asked to produce a frequency table and histogram of the values. In Excel you can do this by selecting Tools, Data Analysis, Histogram from the Menu. For the Input Range you put the cells where the slope estimates are to be found. For the Output Range you can put any empty cell with plenty of blank space below and to the right of it. Make sure that you also check the Chart Output option. You should get a column of frequencies next to a “Bin” column; Excel will automatically select a suitable set of limits for the classes in the frequency table - and then to the right of that you should get a histogram showing the distribution in a visual way. Students were invited if they wished to calculate a suitable measure of skewness.
Now the students were asked to consider a number of questions and to write a brief report on their findings to bring to the class. How does the mean slope estimate compare with the true know value of the parameter (0.6)? How, if at all, is the variance of these estimates of b related to the variance of the X values? Does the distribution of the values as illustrated in the histogram appear to be normal? How different do you think your answers would have been if you had created 1000, or 10000, rather than 100 samples of 25 observations? Explain what is meant by the Sampling Distribution of the Least Squares Slope estimate.
In preparing their reports the students were asked to consult their notes and textbooks on the theoretical properties of the sampling distribution of the slope coefficient, its mean and variance and to consider questions of bias (and unbiasedness).
Overall the exercise was a success in that it provided a concrete focus for a discussion about the properties of the sampling distribution of the slope estimate in a way that was more meaningful than had been possible in previous years (where I could only appeal to students to imagine large numbers of samples of fixed size n being taken from data generated from equation 1). It enabled me also to discuss with the students the benefits both of being able to establish theoretical (asymptotic) properties of estimators analytically and the use of Monte Carlo Studies in cases where this was not possible. It allowed the students to join in the process in an active way, as well as getting them to think about the concepts involved.
The exercise was not without its difficulties, however. More students needed to consult me either by e-mail or in my office hour about this exercise than for any of the other 11 weekly exercises. Some students were initially confused about the difference between the size of each sample (n=25) and the number of replications to be analysed (r=100). This may have been my fault for not explaining things clearly enough in the lecture or accompanying notes. I found that I also had to explain what is mean by a seed when generating random numbers, having failed to mention this point in my lecture. A few students found it difficult to handle within the spreadsheet the large quantity of data generated in the exercise. However, this led to an interesting discussion with one group of students about the how one might design software specifically for Monte Carlo exercises of this type. Since I was about to introduce the students to the use of PcGive in the following week (for regression analysis, not Monte Carlo studies) in some ways it was helpful to be able to point out to students the limitations of spreadsheet packages as well as their advantages, and to discuss the virtues of general purpose and more dedicated software packages.
In retrospect, given that over 80 students take this course, I wish that I had provided slightly different specifications of the exercise to various of groups of students (perhaps giving everyone different sets of X values or even varying the values of b, n, r and au2). Obviously this would have produced a more varied set of results and it might have allowed more students to contribute to the discussion.
As a follow up to this exercise I did offer a Monte Carlo study as one of the options for the students’ assessed coursework towards the end of the course (as an alternative to two other more standard modelling projects). Students were invited to specify their own Monte Carlo study to investigate the effects of autocorrelation or non-normality in the error structure. Only about 10 to 12% of the students opted for this assignment. As a matter of fact the reports produced included both one of the worst (a rather poor rerun of the exercise described above) and one of the best (a thorough treatment of the effect on the properties of least squares estimators of varying the assumptions about the distribution of the error term - considering uniform and t as well as normal distributions, and including the consequences of simple forms of autocorrelation and heteroskedasticity).
Other Monte Carlo exercises of this type can be designed to be given to students. For example you could get them to look at the effect on least squares estimators of measurement error, omitted variables or simultaneous equations bias. They could also examine the standard error of the Y estimate (to see why the degrees of freedom are used in the formula rather than n or n-1).
At a more simple level it might be worth adopting the approach described here to demonstrate to students on a statistics course the validity of the Central Limit Theorem.
Students taking introductory courses in econometrics ought to have an awareness of the use of Monte Carlo studies in the subject. It may help their understanding, not only of the use of Monte Carlo studies themselves but also of important but difficult concepts such as the sampling distribution of an estimator, if they were to undertake a simple Monte Carlo study of their own. Such a study can be undertaken using a standard spreadsheet package such as Excel. Students should, however, be aware of the limitations of using a spreadsheet package for simulations of this type and recognise the benefits of using dedicated statistics and econometrics software tools for more advanced work in the subject.
Judge G (1990) Chaos on a spreadsheet. CHEER Number 11 pp 8-11
Kennedy P (1998) A Guide to Econometrics. Fourth Edition. Blackwell Publishers.
Taylor P (1990) Numerical Analysis Using Spreadsheets. CHEER Number 11 pp 3-7.
Thomas R L (1997) Modern Econometrics. Addison-Wesley.
Wilder L (1999) Investigating Parameter Time Invariance or Stationarity Using Excel Graphs. CHEER Volume 13 Issue 1 pp 4-10
Whigham D and Whyte J (1999) Explaining Input-Output and Equilibrium Relationships Using Excel Display Facilities. CHEER Volume 13 Issue 1 pp 11-15
|
What's Related: · Other articles on the use of spreadsheets in teaching economics |